What 18,000 Events Tell Us About How You Use DevoxxGenie

DevoxxGenie just passed a milestone worth celebrating: more than 72,000 downloads, and in this month alone 29,330 active users firing up the plugin inside IntelliJ IDEA. Thank you. Genuinely.
A smaller, opt-in slice of those users also share anonymous usage analytics. No prompts, no code, no file contents, no personal data, just coarse aggregated signals about which features get enabled, which providers get used, and which models get picked. The goal is simple: stop guessing about what matters and start building for how people actually work.
Even from that opted-in subset, more than 18,000 telemetry events over the past month paint a remarkably clear picture. A few of the patterns surprised me. Here is the story the data tells.
The charts below are real, straight from the dashboard, but they show proportions, not raw counts. This post is about how the bars stack up, not exact figures. Everything DevoxxGenie collects is anonymous and aggregated by design.
1. Local-first isn't a slogan, it's the default
The single loudest signal in the entire dataset: developers run their models locally.

Looking at Feature Used by Provider Type, roughly 85% of all activity went to local providers and only about 15% to cloud APIs. The provider leaderboard tells the same story from a different angle. The top three by prompts dispatched are all local:
- Ollama, by a wide margin the most-used provider
- LMStudio
- CustomOpenAI (local OpenAI-compatible endpoints)
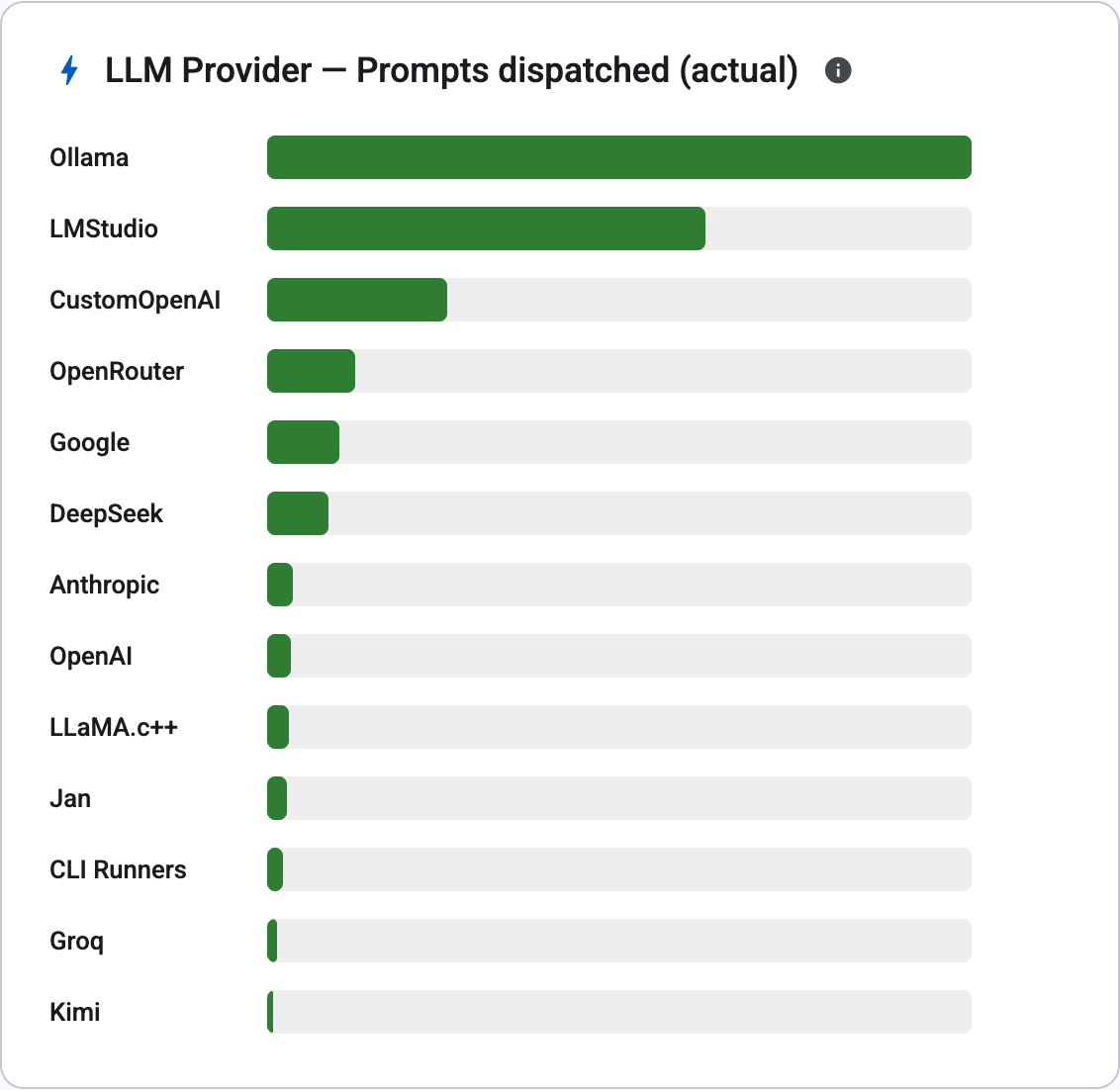
Cloud providers (OpenRouter, Google, DeepSeek, Anthropic, OpenAI) all appear, but they sit well below the local pack. In total, 13 different providers showed up in the data, from the usual suspects all the way down to Groq and Kimi. The breadth of DevoxxGenie's provider support isn't theoretical; people genuinely use the long tail.
The takeaway for the project is unambiguous: local inference is the primary path, and keeping that experience fast, private, and frictionless is the highest-leverage thing we can do.
2. Qwen ate the model leaderboard
If local is the where, Qwen is the what.

Both the "models selected" (intent) and "prompts dispatched" (actual) charts are dominated by Qwen coder variants. qwen2.5-coder:7b leads both lists. It is the most-selected and the most-dispatched model. The rest of the top tier is more Qwen: qwen3-coder:30b, qwen3.6:35b-mlx, qwen/qwen3.6-27b, qwen2.5-coder:14b, and a parade of community quantizations.
Two things jump out:
- Small, fast coder models win. The 7B model out-uses everything heavier. People want a model that keeps up with their typing more than they want the biggest brain in the room.
- Apple Silicon is well represented. MLX builds like
qwen3.6:35b-mlxranking near the top is a clear fingerprint of Mac developers running optimized local inference.
The cloud models that do appear lean toward the cheap-and-fast end too (gemini-2.5-flash-lite, deepseek-reasoner), reinforcing the same "fast feedback loop" preference.
3. People pick a model once, then hammer it
Comparing intent (model selected) against actual (prompts dispatched) reveals a nice behavioral ratio: for every model selection, developers fire off roughly 3 to 4 prompts. qwen2.5-coder:7b, for instance, was dispatched several times more often than it was explicitly selected.
In other words, model-switching is rare. Developers settle on a model and stay in flow. That argues for making the default model excellent and the switching experience cheap, but not for optimizing around constant model-hopping, which barely happens.
4. Agent mode is now the headline feature
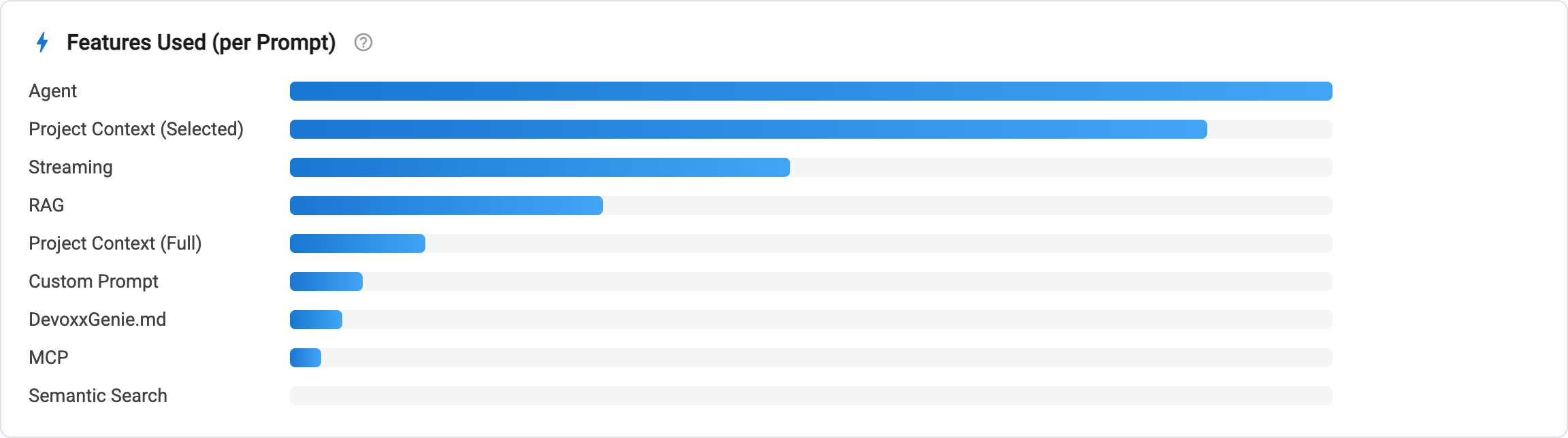
When you look at features actually used per prompt, Agent mode comes out on top, ahead of everything else. Right behind it: Project Context (Selected), then Streaming and RAG.
A couple of details worth highlighting:
- Scoped context beats "everything." Project Context (Selected) is used far more than Project Context (Full). Developers are deliberate. They hand the model the files that matter rather than dumping the whole repo. Good instinct, and good for token bills.
- Streaming is the expected default. A large share of prompts stream their response. Watching the answer arrive token by token clearly beats waiting for a wall of text.
On the enabled per session side, Custom Prompt is switched on in about half of sessions, followed by Agent (about 24%), Streaming (about 11%), RAG (about 7%), MCP (about 6%), and Web Search via Tavily (about 3%). The headline features get broad adoption; the advanced ones have a smaller but committed following.
5. MCP and long memory are power-user territory
Two of the smaller panels are quietly the most interesting.
- MCP servers per session: most sessions run zero MCP servers, but a meaningful cluster runs 2 to 5, and a handful push into the 6 to 10 range. MCP is a power-user feature, and the power users are clearly stacking servers.
- Chat memory: the vast majority of sessions sit in the highest memory bucket (21+ messages). These aren't one-shot questions. They are long, sustained conversations where context accumulates. That validates the work on chat memory management and persistent memory.
Meanwhile, the Semantic Search tool barely registers yet. It is the newest arrival, so low adoption is expected, but it is a flag to make the feature more discoverable.
What this changes
None of this is collected to surveil anyone. It is collected so the roadmap reflects reality instead of my assumptions. A few decisions fall straight out of the data:
- Double down on local. Ollama, LMStudio, and CustomOpenAI are the main stage. Their setup, speed, and model management deserve the most polish.
- Treat Qwen coder models as first-class citizens, including MLX builds for Apple Silicon.
- Keep investing in agent mode. It is no longer a side feature, it is the feature.
- Make newer capabilities (Semantic Search, MCP) more discoverable, because the people who find them clearly get value from them.
With 72,000+ downloads and nearly 30,000 active users a month, every one of these choices now lands in a lot of editors. If you'd rather not contribute any telemetry, that's completely fine. It is opt-in and easy to turn off in settings. But if you leave it on, know that it is directly shaping where DevoxxGenie goes next. Thank you for that. 🙏
Curious about exactly what is and isn't collected? It is all defined by a closed-enum schema. Only known, non-identifying values are ever recorded, and anything outside the allowlist is dropped.