Watch Your LLM Think: Reasoning Now Visible in DevoxxGenie

Reasoning models don't just answer. They think first. They talk themselves through the problem, weigh options, and correct course before committing to a reply. Until now, all of that happened invisibly: you saw the polished answer, but never the reasoning that produced it.
Starting with DevoxxGenie 1.8.12, you can watch it happen. Turn on Show Thinking and the model's chain of thought appears in its own dedicated 🧠 section, streaming live, right before the final answer.
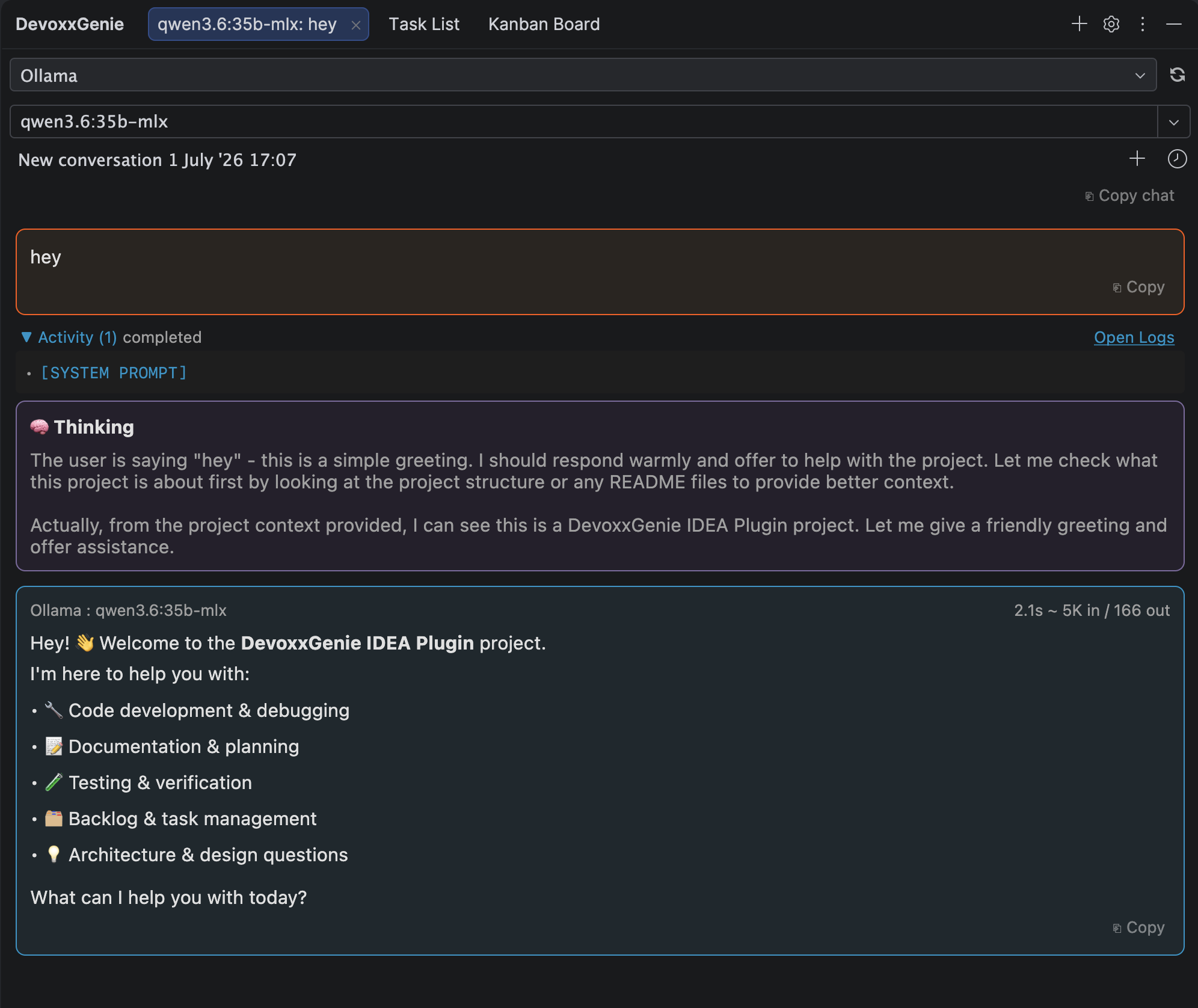
In the screenshot above, a simple hey triggers the model (qwen3.6:35b-mlx running on Ollama) to reason out loud: it recognizes the greeting, checks the project context, and then decides how to respond. The 🧠 Thinking block captures that internal monologue, and the final answer follows below it, cleanly separated and never tangled together.
Why this matters
Seeing the reasoning isn't just a novelty. It's genuinely useful:
- Trust and transparency so you understand why the model landed on an answer, not just what it answered.
- Debugging prompts, because when a response goes sideways, the thinking often reveals exactly where the model misunderstood your intent.
- Learning, since watching a strong reasoning model work through a hard problem is a surprisingly good way to sharpen your own approach.
- Catching mistakes early, because if the reasoning is off, you'll often spot it before the final answer even finishes streaming.
One checkbox to turn it on
The feature lives right next to the existing stream setting. Open Settings → DevoxxGenie, find the Large Language Model Response section, and tick Show Thinking.

That's it. When enabled, reasoning models expose their thinking in a separate section before the final answer. When disabled, behavior stays exactly as it was before, so nothing changes for models that don't reason, and you're never surprised.
Works with the models that reason
Thinking is surfaced for reasoning capable models across providers, including Ollama, LMStudio, Jan, Llama.cpp, DeepSeek, Mistral, and more. DevoxxGenie requests the reasoning stream through LangChain4j and renders it as its own theme aware block, so it looks right in both light and dark IDE themes.
It works in both modes:
- Streaming, where the thinking appears token by token as the model reasons, then the answer streams in below it.
- Non streaming, where the full reasoning is captured and shown above the completed answer.
Either way, your token metrics and final answer text stay intact. The thinking is additive, never a replacement for the response you actually asked for.
Try it
Point DevoxxGenie at any reasoning model you already run locally, such as a qwen3 on Ollama, flip on Show Thinking, and ask it something that requires a bit of deliberation. Watching the model reason its way to an answer changes how you read its output.
DevoxxGenie is open source on GitHub with issues, ideas, and stars all welcome. 🧠